- 产品中心

- 关于我们


腾讯科技AI未来指北-AI探索者系列,对谈AI产业的躬身入局者,关注AI大模型落地第一程的关键问题。本期联合腾讯研究院,对谈澜码科技创始人周健,关注大模型落地B端的关键思考。
文 / 腾讯科技 郭晓静


腾讯科技:从现在的AI手机和AIPC中没有看到什么苗头吗?
周健:现在太早了,还是概念阶段。
现在主要是硬件需要准备好了,比如最近苹果说M4芯片是为AI做的。
腾讯科技:目前的硬件厂商已经说能支持7B、13B的模型在端侧运行了,所以现在的阻碍是不是已经不在硬件了?
周健:现在的问题在于13B的手机端侧模型,对于我们这样的toB Agent的厂商也是一样的,任何一个模型厂商发布一个产品,只有模型的参数,这让我们怎么用呢?
现在是模型产品定义的第一关还没过,第一关就是模型小型化之后,它的featurelist究竟是什么?怎样定义这个模型产品是符合手机端、符合PC端?它有什么基本能力?
这关过了之后,后面才到了我们到底需要再什么手机上配什么算力、装什么模型。
腾讯科技:现在看到厂商在定义,我用这个模型可以做图片消除、文件管理等等。
周健:这件事儿不应该是手机厂商去做。
手机厂商没法定义,他们定义完,模型厂商做不到,这怎么办?或者说这确实是先有蛋还是先有鸡的问题。先不谈手机,先谈部署在云端的模型,13B、33B、130B,他们的边界是什么?什么场景应该用什么模型?这些都还没有。
可能我们作为TOB的企业,已经突破了很多场景,但是这些场景拿出来之后,有没有模型厂商可以给出一个特定的featurelist?更不要说端侧了,因为要把端到端的应用跑通就更难了。
TOB服务还可以说我用目前性能最强的服务先验证一下。端侧如何验证呢?我觉得可能需要我们的这样的厂商先和模型厂商对齐。
商业上其实和学术上很不一样,商业上肯定是先要对大模型的能力边界和品类进行定义,到底有哪些大的品类,每个品类的能力边界是什么,这些基本问题,模型厂商需要首先回答出来。
腾讯科技:大模型的品类指的是什么?比如某种能力突出,长文本算吗?
周健:一个feature的定义,是市场上大家一起去决定的。现在最小的模型算力可能只需要一张4090消费级显卡,大一些的模型,从推理上来讲,可能要100张A800显卡。算力差100倍的情况下,肯定要分成不同的品类。比如一件普通的T恤和一件奢侈品,价格就可以从几十块到几万块,但是你可以给这个定价一个理由。
但是如果模型的商品定义体系不出现的话,其实商业化落地是没有办法迭代的。
腾讯科技:大模型技术文档定义的参数,对你们来说是没有太大价值吗?
周健:关系不大,我们买的是衣服,不关心制作流程。
腾讯科技:这事儿未来要谁来做?
周健:肯定是大模型厂商。现在还是“乱哄哄”的,包括现在发布出来的各个应用场景的落地的成本计算也没有变成共识,如果慢慢变成共识了,整个生态就开始转起来了。
腾讯科技:大模型落地应用这件事其实大家都还没想清楚。
周健:应该在什么场景落地大模型的应用,现在实际上大家是抓狂的。
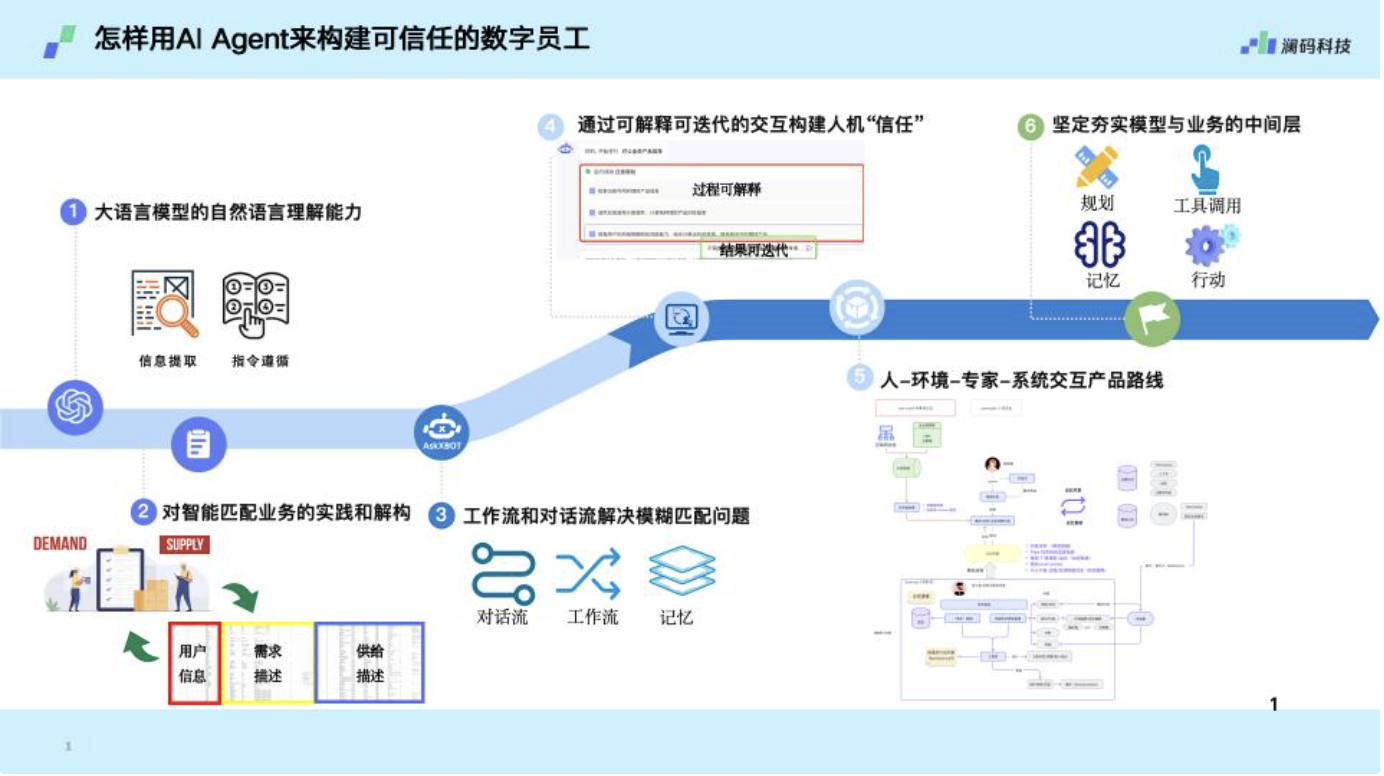
我们自己的探索是,如刚刚提到的,大模型的个性化定制成本低、语言理解能力强,可以解锁一些传统做不了的新场景。比如之前中小企业的信贷审核,靠AI是做不了的,或者原来做起质量很差;比如保险代理,过去也是做不到的。
我们其实是通过AI Agent加上知识库,解放专家的时间,变成新的生产力。过去领域专家时间的供给是一个瓶颈,现在可以通过AI去突破这个瓶颈,原来不能做或者不能批量做的事情现在就能做了。
我觉得和大家理解的不一样,大模型能带来的收益首先不是降本增效,更多的是增收和合规。降本增效更容易一些,TOB的企业优先想做的肯定是增收和合规。

腾讯科技:AIAgent能类比移动互联网时代的APP吗?
周健:Agent最重要的事情是它和环境之间的互动,其实就有两条边,一条边是从环境中感知,另外一条边能产生Plan,然后做出行动去执行。
它不是APP,今天我们看到其实更多是在原有的APP上增加了AI能力,比如说今天任何一个应用,都可以通过自然语言的对话,来发出指令。这不是Agent。
Agent重要的是要和环境感知互动,刚刚说的那种,只是传统软件的AI化。
腾讯科技:创业公司巨大的机会是挖掘这些加AI的需求吗?
周健:巨大的机会肯定不在这儿,传统软件加AI是传统软件可以去做的。巨大的机会在AI原生的应用。
在Agent的生态中,已有软件都可以作为Agent感知环境的一个组件。其实我们不是和传统软件竞争,而是赋能传统软件,成为下一代的入口。
比如我们做数字员工,我们把员工的意图识别成专业知识库,拆到原有应用中。其实AI原生应用是全新的品类,它站的生态位置是人跟系统的中间又多了一层。它会代理人的意图,拆解计划并完成工作。这个工作可以是操作各种各样的系统。
所以这个意义上来讲,AI原生完全是全新的机会,跟传统软件、APP没关系。这是一片新大陆,具体在哪里,还得再探索。
腾讯科技:但是听起来,未来的AIAgent还是很需要传统软件?
周健:需要的。我们的假设不是没有信息化,信息化是数字化的前提,数字化是AI化的前提,我们的前提是前面已经数字化好了,如果是没有数字化,比如说像猎头行业、律所行业,因为他们没有信息化,没有数字化,这个就很困难。
腾讯科技:过去其实企业数字化的推动就很难,这会成为TOB落地AI的阻碍吗?
周健:其实很多大企业的决心挺大,基础设施都准备好了,但是落地的场景没有找到。这部分的需求还是挺大的。
腾讯科技:那对于你们公司的产品经理来说,是不是还需要了解每个特定行业的工作流?
周健:对,他自己也要是业务专家,没有靠谱的业务专家是做不到的。但是会有两层,一层是业务的产品经理,比如银行、保险、券商、能源,他一定要了解行业。
另外一层是做平台的,不需要特别了解业务,但是需要通过定义好的能力文档、数据流程来做产品。
腾讯科技:未来企业的工作流程会发生怎样的改变?
周健:现在其实是人跟人之间的分工协作,会有很多信息的断点、数据的断点、知识的断点,这是人的带宽所造成的。
比如从管理学上讲,人的带宽最多只能关注到7-15个人。随着大模型的不断演进,大模型的记忆能力会越来越好,其实这就会把流程上的断点帮助填进去。
企业最重要的是放大竞争优势,而不是补上短板。竞争优势一定是一线和后台的通力配合,“让一线能够听见炮火的人呼唤炮火”,但是传递信息的带宽有限,可能后台专家收不到这个信息。
但是如果每个员工都有一个Agent,既可以把一线情况不丢失地带到后方;后方的决策又能直接传到一线的各个地方。
腾讯科技:那实际上是帮助人提高带宽,未来人的核心能力又变得更大了?
周健:人主要知道该做什么,去下达任务。今天的AI实际上还有一个很大的瓶颈,没有内部的世界模型,并不能自我学习。
现在人类做决策很大程度是靠直觉,就是我们能自动找到相关性,在我过去的经验中,有哪些事情相关、当时我采取了什么办法来解决这问题。这是我短期之内看不到AI可以去替代的。
目前的Scalinglaw路线其实还是蛮力,未来全世界的能源都不够AGI用的,所以我觉得这条路是有瓶颈的。从过去的规律来讲,人不是被设计出来的,而是慢慢进化来的,进化才是最强的力量。
所以短期看不到AI对人类的替代,但是我们要学会怎么去拥抱它,变成新的劳动者。知道它的能力边界在哪里,在未来的职场中占据一个好的位置。
腾讯科技:人类的基础科学还是像烟囱一样,没有融合和打通?
周健:对,历史上出现过做量化投资的公司,因为一个程序Bug导致这个公司破产。我觉得现在倒是不用担心AI统治人类的事情,而是因为人类的粗心,或指令的错误,带来系统性的灾难。这个可能是最值得担心的事儿。