- 产品中心

- 关于我们

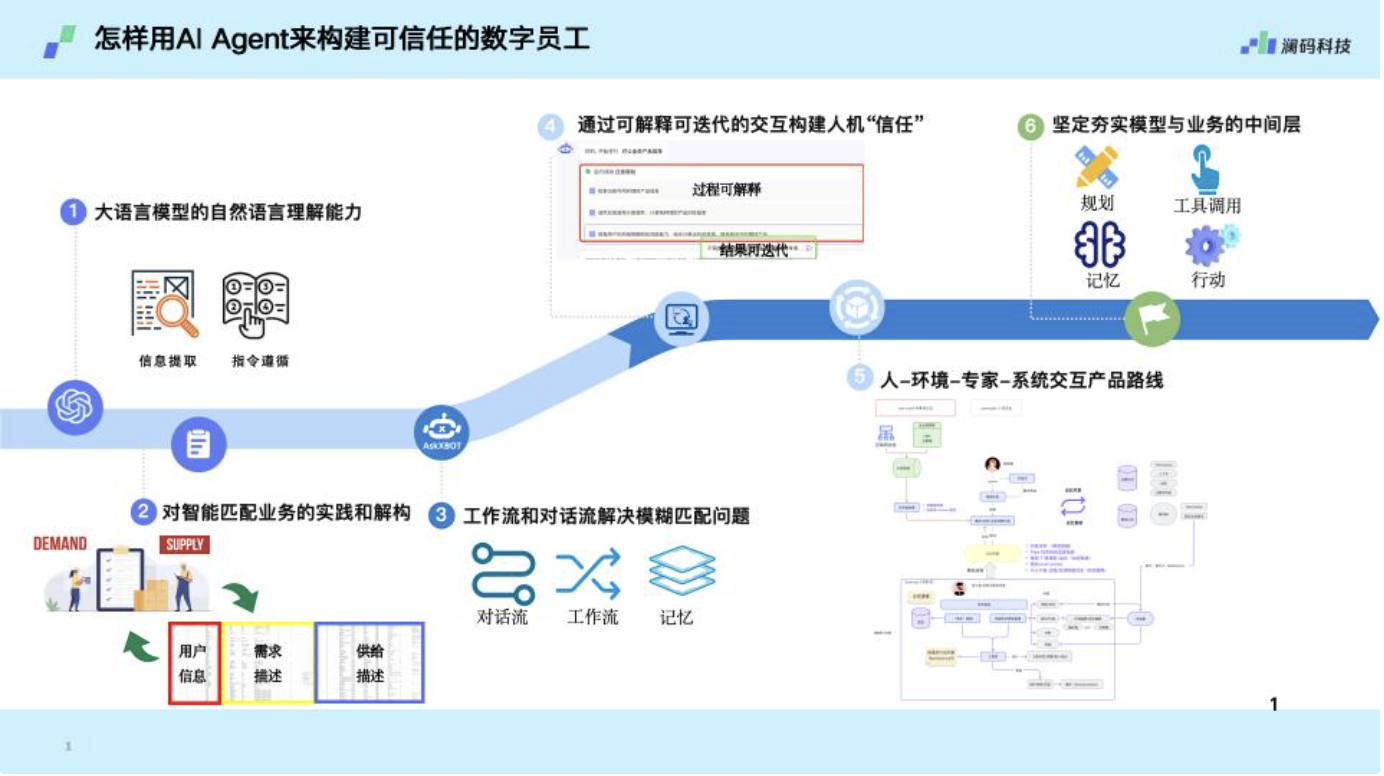
从人类的认知系统看AI Agents
今天的AI与人类相比较,在认知系统层面的差异具体体现在哪些方面?
-
优点是响应迅速,但在复杂任务中表现可能不理想。
-
反应快但改变较慢,就像人类的习惯难以快速改变。
-
通过生成中间推理步骤来解决问题。依赖记忆调用,存储思考过程和对行为结果的反思,累积经验以优化后续行为。
-
反应时间比系统1慢,但改变所需时间相对较快。
-
优点是推理能力强,不过需要更多计算资源和时间。
Agent认知系统的架构
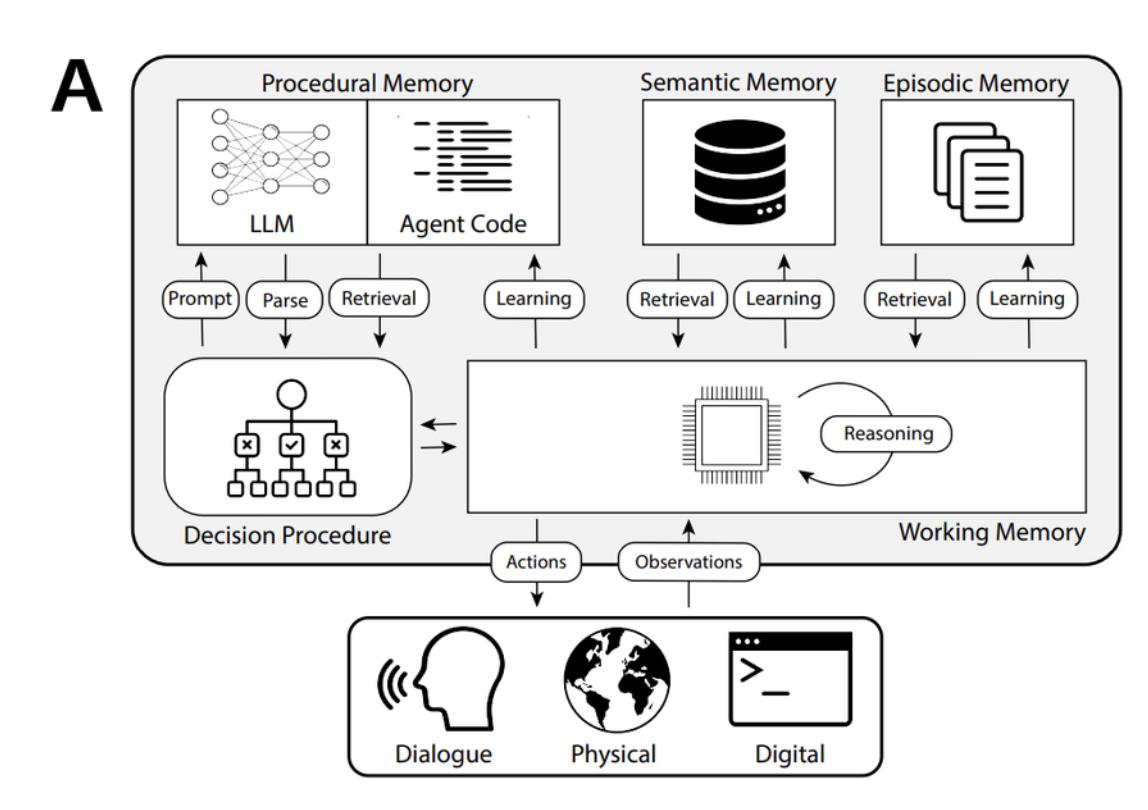
感知是获取外部信息的通道,就像我们的眼睛和耳朵感知世界一样,Agents 通过传感器收集数据。
学习则是不断优化自身能力的过程,通过大量的数据训练,提升对各种情况的理解和应对能力。例如,在自动驾驶领域,车辆中的Agents需要不断学习交通规则和不同路况的处理方式。
推理是根据已有的知识和信息进行逻辑思考,做出合理的判断。
决策则是基于推理的结果选择最佳的行动方案。
结合CoALA框架,我们按照信息的内容,将信息组织进Agent的多个记忆模块,包括短期工作记忆和三种长期记忆:情景记忆、语义记忆和程序记忆。
-
程序记忆(Procedural Memory):存储⽣产系统本⾝Agent⾏为的规则集和程序。
-
语义记忆(Semantic Memory): 存储一些基础知识、世界知识。
-
情景记忆(Episodic Memory):存储Agent过去的历史事件流或者行为经验。
这些记忆组件共同构成了CoALA框架下Agent的记忆系统,使得Agent能够存储信息、进行推理、做出决策,并从经验中学习。
短期(工作)记忆是如何工作的?
信息处理(Grounding Action)将Agent执行动作后,得到的环境反馈处理成文本,输入到工作记忆中。
检索(Retrieval Action)将信息通过规则或密集检索等方式,从长期记忆中读入工作记忆中。
推理(Reasoning Action)使Agent能够处理⼯作记忆的内容以⽣成新的信息。与检索不同,推理是从⼯作记忆中读取并写⼊⼯作记忆。
长期记忆是如何工作的?
-
程序记忆的更新:更新推理、检索、新学习或者决策的方法。
-
语义记忆的更新:将世界模型中一些基于事实归纳的信息写入语义记忆。LLM通过推理原始经验并将结果推论存储在语义记忆中,为工作记忆中上下文理解等提供依据。
-
情景记忆的更新:用“经验”更新情景记忆。Agent通常存储情景轨迹以更新或建立策略。Agent检索情景记忆中的附加经验可以作为推理或决策的示例。

Agent记忆的实现
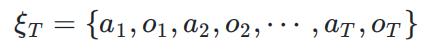
该定义来自于《A Survey on the Memory Mechanism of Large Language Model-based Agents》
我们将Agent的记忆按照来源不同分为三大类:
-
Trial内的信息:同⼀个 Trial 内的历史信息。Trial 内的历史信息与未来的动作是最有关联的,⼏乎所有模型的记忆都包含 Trial 内信息。然⽽,完全只依赖 Trial 内的信息作为记忆可能会让Agent⽆法有效积累知识。
-
跨Trial的信息:其他 Trial 的历史信息。跨 Trial 的信息能使Agent积累多种成功与失败的案例,总结失败的原因或成功的⾏动模式。
-
外部知识:⽆论 Trial 内的信息还是跨 Trial 的信息,都要求Agent去与环境进⾏交互才能获得,⽽外部知识可以让Agent直接获取⼤量的、最新的、质量良好的信息。

我们将Agent的记忆按照类型不同分为两类:
-
完整的历史信息
该⽅法在上下⽂中记录所有历史信息,虽然可以存储⼤量信息,但要消耗⼤量计算资源、推理时间,超⻓的上下文也会影响 LLM 的准确性与稳定性。
-
最近的历史信息
只存储最近的信息能提升记忆的利⽤率,但在⻓期的任务中,该⽅法容易忽略⻓距离依赖的关键信息。
-
⽤于检索的历史信息
检索的⽅法基于内容的关联程度、重要程度来选取记忆信息,不依赖于时间,因此不会忽略⻓距离的重要信息。该⽅法⾮常依赖于检索策略的准确度与效率,且需要信息以统⼀的⽅式存储,不能直接应⽤于处理外部环境中多样的信息。
-
外部知识
2. 参数形式:参数形式的记忆隐式地影响模型的⾏为。
-
微调
微调能有效地将专业知识注⼊ LLM,但可能导致过拟合,使 LLM 遗忘原本的知识。微调需要⼤量的训练数据,以及计算资源和时间消耗。微调也不能很好地处理与环境的动态交互,因此主要被应⽤于离线任务。
-
知识编辑
知识编辑能修改特定的知识,并保持其他⽆关的信息不被影响。知识编辑适合⼩规模的记忆修改,它需要较⼩的计算资源,更适⽤于在线的任务。
综上,从有效性、效率和可解释性来说,两种记忆存储形式有如下优劣:

根据不同的场景和应用,我们需要对文本形式和参数形式这两种类型的记忆进行权衡。文本记忆适用于需要回忆近期交互的任务,如对话和上下文特定的任务。例如,在Agent与用户进行对话时,需要回忆之前的对话内容来理解当前的语境,这时文本记忆就可以发挥作用。对于需要大量内存或成熟知识的任务,参数记忆可能是更好的选择。
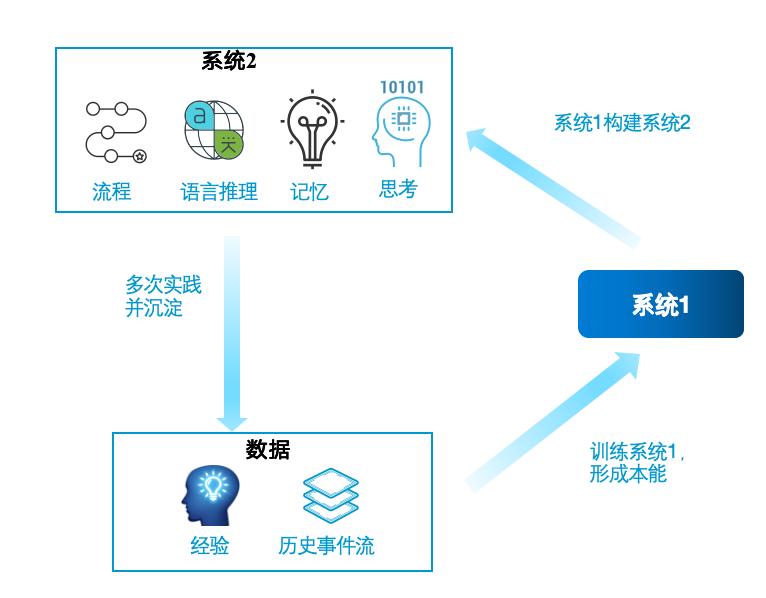
通过对人类认知系统的深入理解,我们发现让Agent拥有类似于系统2的能力是至关重要的,这将使它们能够更好地解决复杂问题。
在未来的研究中,我们需要进一步探索如何让每个Agent都具备系统2的能力,使其能够充分调用长期记忆、进行计划和反思,从而更好地解决复杂问题,实现从系统1到系统2的扩展。同时,持续优化Agent的认知架构和记忆实现机制,也是提高Agent性能和智能水平的关键。
参考文献:
-
https://arxiv.org/pdf/2309.02427 《Cognitive Architectures for Language Agents》
-
https://arxiv.org/abs/2404.13501 《A Survey on the Memory Mechanism of Large Language Model-based Agents》
-
https://mp.weixin.qq.com/s/m-3HSVp0WLVSlw72pjIXiQ
-
《Thinking, Fast and Slow》 Daniel Kahneman