澜码创始人周健长江独角兽峰会分享:AI Agent如何为千行百业赋能 随着大语言模型技术的飞速进步,业界对人工智能的讨论已从概念炒作转向关注大模型的实际应用及如何引领生产力革命。
5月9日,由长江商学院主办、汕头大学协办的“2024长江独角兽峰会”在深圳隆重举办。峰会以“AI驱动的未来”为主题,汇聚数十位全球商业领袖、独角兽企业创始人、投资人以及知名专家学者,共同探讨科技产业版图加速重构下,AI驱动的新质生产力变革。

作为国内探索大语言模型应用落地和企业级AI Agent的先锋,澜码科技创始人兼CEO周健受邀参与本次峰会,分享AI Agent 赋能千行百业的实践与思考。
参与本次峰会的嘉宾还有长江商学院院长李海涛、图灵奖得主Joseph Sifakis、微软中国首席技术官韦青、360集团创始人周鸿祎等。
在演讲中周健提到,大模型将重塑企业,极大地释放数据要素中的生产力。大模型的“能力涌现”现象,可以完成以往人工智能无法完成的任务,突出表现在信息快速提取能力、指令遵循能力、智能体的互动适应能力三个方面。此外,以大模型能力为底座的AI Agent作为一种新型生产力,将极大满足企业自动化数字化升级需求,彻底颠覆企业形态。
以下为澜码科技创始人兼CEO周健的演讲全文,我们做了不改变原意的整理和编辑,以飨读者。

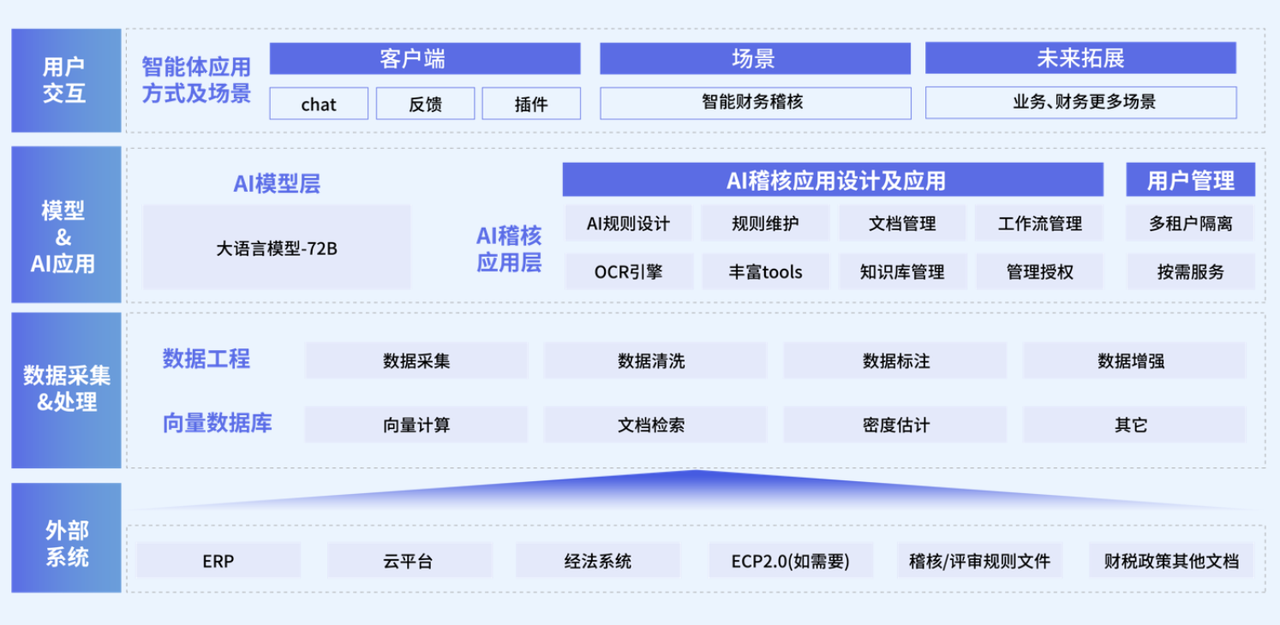
澜码科技是一家做大模型应用落地的公司,聚焦于企业服务领域,我们希望将AI Agent同ToB应用结合起来、赋能千行百业。
公司的实质就是将员工组织起来,来为同一个经济目标服务。我们现在所讲的数字员工或者AI Agent,其实就是希望在企业业务流程中,实现人机协同、人机融合乃至人机共生。AI Agent在其中的价值,就在于依托大语言模型的能力,将企业内部的知识、数据的生产力释放出来。
从我们的角度来看,大语言模型能力涌现主要体现在三方面。
第一是信息快速提取能力。这是最简单,也是最能直观感觉到的。我们都听过一个词叫“自然语言处理”,在过去要处理各式各样的文档、周报、聊天记录是件十分困难的事。但依托大模型的涌现能力,今天可能一个Prompt工程师一个礼拜的工作量就可以解决这个问题。这也是当前AI拥有的一个变革性的能力。

第二个是指令遵循能力。在过去,我们用自然语言发出指令,需要程序员将其翻译、配置成规则,但现在完全可以依靠大语言模型理解后执行。以招聘场景为例,一个专家定义好“工作稳定”是指工作五年的工程师需要每份工作时长必须大于 18 个月,大语言模型就可以理解、执行命令了。从程序员的视角看,过去我们拿到文本,从中抽取信息出来都十分困难,更不要说执行文本中包含的“专家命令”。这就像哈利波特的“咒语”,一下子就将其中的能力释放出来了。
那么智能体是什么呢?通常定义里,AI Agent是LLM+Plan+Memory+Tool use,但在我看来,智能体不仅需要与人互动,更重要的是,还要有适应人的能力,这也是我要讲的第三层能力。以最简单的BI报表为例,每个人的水平不一样,大模型呈现出的结果就不一样。初级的用户不懂术语,可能需求都表达不清楚,这就需要AI 循循善诱,不停地提问。
但AI Agent不同,如果我们设计一个能够适应用户水平的 AI Agent,通过观测、分析用户懂什么、不懂什么,就可以帮助用户解决问题。相比于纯粹的大语言模型,AI Agent可以弥补其中“千人千面”的部分,我认为这就是AI Agent自身的巨大变化。
大模型泛化能力强,开发周期短、边际成本低,是AI开发的新范式。我自己从一家明星创业公司辞职、并选择创业,就是因为我看到了这个可能性。
具体来说,一是个性化定制成本大大降低,二是我们正迈向智能摩尔定律时代,模型的成本大大降低。
从ChatGPT-3.5到现在,大约一年半的时间,GPT-3.5的使用成本已经降到原来的1/100,国产大模型也是如此,这就为我们做应用落地的公司提供了机遇。
我们认为,AI智能体是一种新型的生产力,它由算力、模型、数据和专家知识等生产要素组成。我们希望做的AI Agent是在数字环境中的智能体,并非是自动驾驶或具身智能等物理世界的Agent。
数字环境里有数据、文档、应用、流程等等,人通过IM工具聊天,我们希望作为用户的Agent,帮助他更好的完成工作。
另外,专业知识对AI Agent也十分重要。一方面,专家知识可以提升Agent的业务能力;另一方面,通过算力,我们可以将专家知识变得可以复制,比如原本专家一天只能处理10份报告,现在用算力就可以复制专家的能力——有10张显卡就能处理100份报告。将专家知识整合进去,就会形成一种新质生产力。
我们也期待大模型涌现的能力越来也多。比如会不会有情绪的智能、社会的智能?我们也期待大模型未来的发展,让我们用更低的成本去做更多样化的场景。
专家知识作为“燃料”
除了增强自动化,即专家知识赋能AI Agent让员工更强以外,生产关系也将发生变化。
AI Agent作为员工可以有两个角色,一个是“观众”,一个是“演员”,两者其实完全是不一样的。
有一个管理科学的实验,即当员工觉得被观察的时候,他的行为也会发生改变。所以AI Agent是有可能改变生产关系,改变(传统的)人机协作的企业业务流程。
我们认为企业的AI转型也会经历三个阶段:第一阶段,转型准备期。需要对全员培训,需要全员开通类似 GPT-4 的账号、Midjourney 账号,大家会做各种各样的日常的“小成效”。
第二个阶段就要开始应用迭代了。现在我们用的比较多的AI工具,比如大家都听说过的RAG技术,企业内部的知识库、产品手册、价格信息、客服记录等,挂一个 RAG 作为各种助手,如问答助手、办公助手、客服助手、代码助手等,这就有非常多的应用了。同时,在国内特有的情况下,会很多私有化部署,其实也会有特别多的应用场景。
第三个阶段,进入到我刚才讲到的信贷报告案例所处的阶段,即业务突破期。它需要改变一些流程,因为这个业务在原来的情况下是做不了的,以前专家一天只能做三份、五份报告,现在相当于把专家知识灌进来,First line 可能是初、中级的员工, Second line 是Agent, Third line 是专家,就可以大大提高整体的工作质量、降低风险,甚至实现业务创新和增收。
这里就开始进入到深水区,因为已经要开始去改变一些流程,从而获得更好的结果。最难的就是业务突破,比如刚才演讲嘉宾提到的“鞋类大模型”让我看到了希望,有可能红蜻蜓可以做出来 Better product,这需要一把手,需要有科学家,需要有团队。
总结一下,在这个过程中,我们看到的是专家知识的重要性,但是这里提到的知识跟我们过去理解的、特别是技术侧讲的知识图谱是完全不一样的。
知识图谱更多的只是一些点状的,比如什么是马?什么是白马?是马的子类、马的颜色属性之类等等。但现在的知识,其实有事实性的知识、规则性的知识、过程性的知识。
拿财务岗位举例,比如会计科目,可能一本教科书就可以把这些东西全部都记录下来,没有必要去让大模型训练。比如985、211高校的信息一直在变,专门去训练一个懂得什么是985、211高校的大模型一点也不划算,这时就可以外挂一个知识库,用 Agent的方式去实现。
但是冰山下的,比如这里讲的领域性知识、社会性知识就进入深水区了。一方面专家不见得愿意说,另外一方面他可能也说不出来。

举个极端的例子,对于核电站的专家来说,全世界核电站一共就爆炸过几次,专家怎么说的出来到底什么时候应该怎么查?这个知识到底在哪?社会性知识就更难了,怎么判断这个组织里谁靠谱?应该找谁?这些其实都是特别难的。
长远来看,大语言模型应该是解决不掉私域知识问题的,因为这是企业内部最核心的知识,或者必须要躬身入局才能拿到这些知识、在大模型的支撑下做出一个企业的数字员工。
刚才(圆桌环节)在讨论AI Agent公司或竞争对手相关问题,同时这也是我一直会被人问的一个问题——如果OpenAI做了澜码科技正在做的事情,你应该怎么办? 其它的大模型公司会不会也做?在我们实践过程中,我看到了专家知识的重要性,这会是未来我们的一个壁垒。
未来,业务流程也会在AI的变化之下慢慢去改变,这里十分重要的还是关于知识。我觉得企业未来是知识经济,但是过去的知识更像是文档中心,今天有机会更好地把知识中心重新做一遍,做到让知识能够作为一种“燃料”或催化剂,让大模型发挥更大的价值。
AI Agent将是内置大规模行动模型(LAM)
的企业智能化助手
下面的部分是我们自己设想的未来可能的一些变化,即AI Agent 将成为内置大规模行动模型(LAM)的企业智能化助手。
这也是 Sora 给我的启示,即只通过文本和视频是学不会游泳的,大模型在企业里是做不了CFO 的。如果在企业内部,有能够去收集各种各样行动的Agent,能够做到对员工下一个行动的预测,有了Next Action Prediction,从而使得Agent能够变成一个更好的、合格的数字员工。
大家在讲未来的人力市场会是什么样,其实现在有很多的公司比如代记账、猎头、律所,已经实现了业务流程外包,把企业非核心流程外包出去、按件收费,未来如果有了靠谱的、类似淘宝之于电商的一个能够售卖服务的平台,就能够去解决专家跟Agent之间的匹配问题。
OpenAI现在做 GPTs,最大的问题是没有解决匹配问题。苹果的 APP Store,一开始应用也不多,靠人能解决这个问题,但大模型一下子涨到几亿 DAU,就无法“手工”解决了。
今天我们还处于行业的最早期,大模型作为一个商品,它的 Feature Spec是什么?如果只用一个参数去表达产品的 Feature Spec是不够的。相应的,我们作为一家AI Agent厂商,我们做出来的 Agent也需要有 Feature Spec,这些解决完后,GPT Store 才会成立。当然现在技术上还有差距,也许GPT-5 出来后会解决这个问题,而解决之后整个劳动力市场就会发生突变。
当然,现在行业内也还有很多问题,一方面是今天有很多算力,但是不知道应该在上面做什么、怎么用;另一方面是算力缺乏。
比如在银行业,我们目前主要的是金融客户,六大行、12个股份制银行有千万级的算力,再往下的城商行就不一定有这样的算力资源了。
我昨天去了一个城商行,它对外借了 24 张卡才可以去做一些大模型的尝试。而再往下一层的农商行就更缺少算力了,也就是说,即使是银行也不完全有能力去购买算力。所以这里还是有一个机会,即通过 Agent市场的专有云,把它匹配起来,形成一个所谓的新质生产力。
我猜想,未来可能会形成一种新的生产力平台,比如生产力开发者的“淘宝”,类似猪八戒的升级版一样,中国的AI时代会催生这样全新维度的(生产力)交易平台。