- 产品中心

- 关于我们


作者丨何思思
编辑丨林觉民
他是亚洲首个 ACM 国际大学生程序设计竞赛世界冠军团队成员;
他是谷歌中文网站搜索质量优化工作的负责人;
他是AI四小龙依图科技的第10号员工;
他是李开复50个“关门弟子”之一...
他也是澜码科技的创始人。
缘何命名为澜码?周健这样说:寓意波澜壮阔的代码。
澜码科技于今年2月份在上海成立,与其他创业公司不同的是,澜码科技想做的是基于大模型打造新一代的自动化平台。
虽然成立时间不长,但澜码科技已于近期完成了数千万人民币的A轮融资,其中IDG资本、联新资本、Atom Capital三家参与了本次投资。
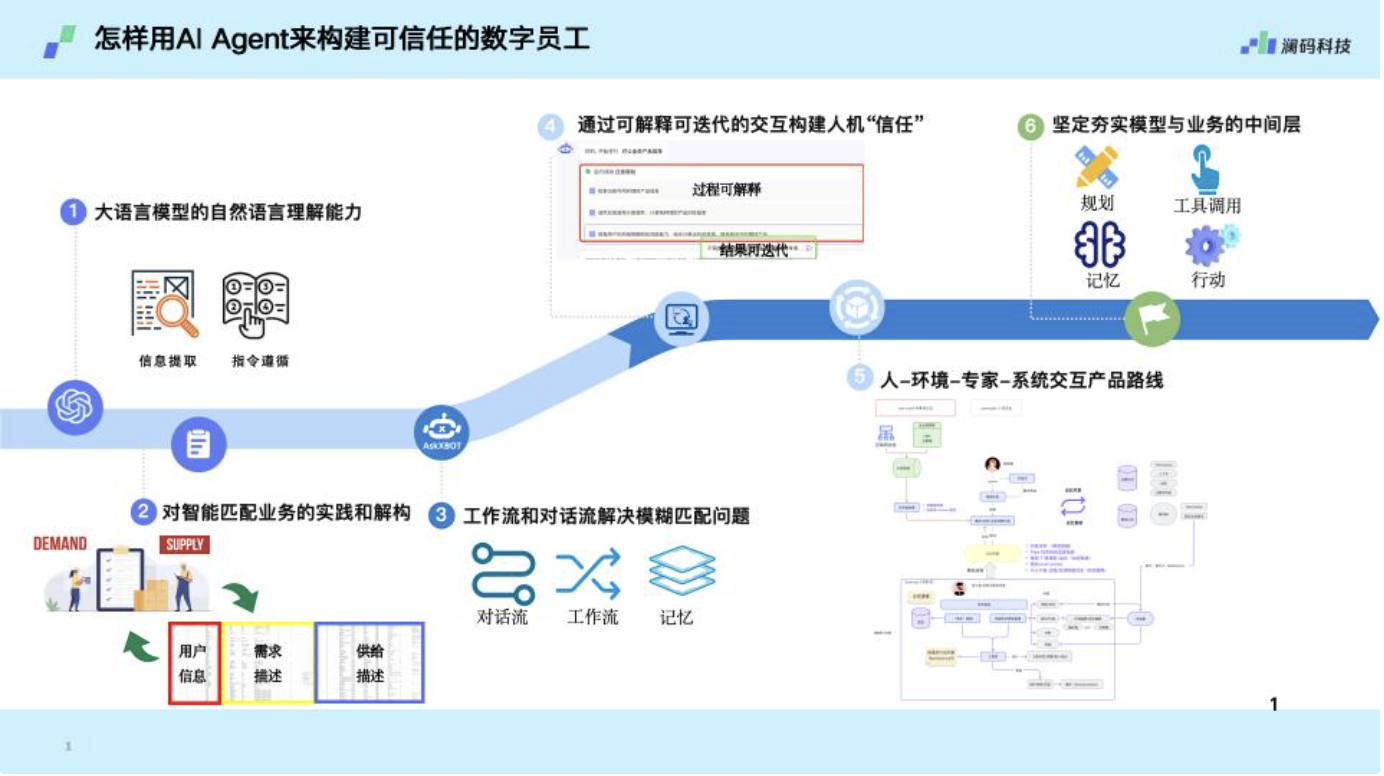
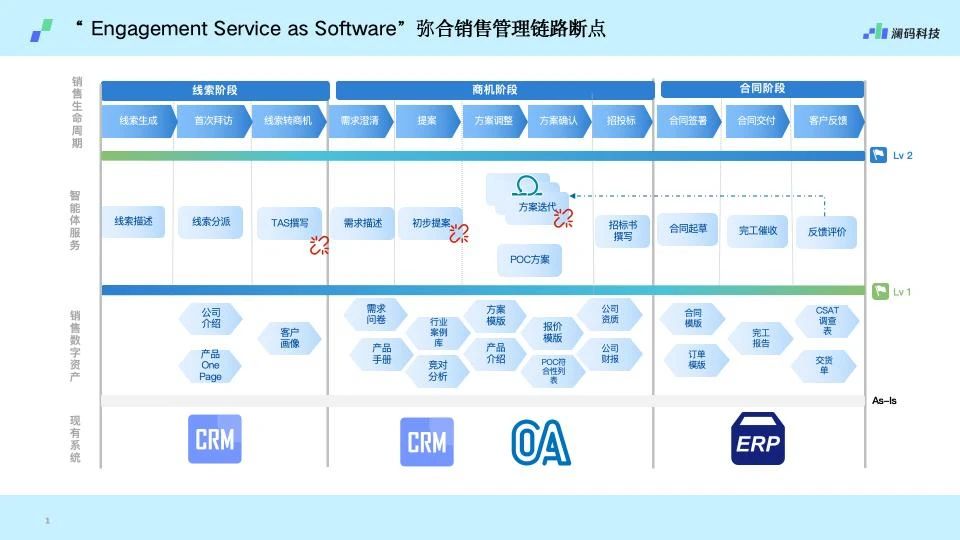
另外在产品层面,澜码科技已经成功研发出了Agent平台Ask XBot。AI科技评论了解到,其操作主要分为两层,第一层由专家通过传统、新兴的对话交互的方式定义工作流程;第二层由一线员工通过自然语言指令,控制机器协助完成数据分析、资料调取等工作。
谈及短期内缘何能受资本如此青睐?周健告诉AI科技评论:“早期投资资方首先看的是创始人本身的特质,然后才是商业化能力。”
显然这两者方面,周健都具备。一方面,周健本人从业经历丰富,且澜码科技的核心成员均来自依图、阿里、腾讯、Google等头部企业;另一方面,大模型技术将带来交互方式的变革,澜码科技基于大模型的自动化平台,不仅顺应了AI 2.0的发展,还符合企业以及人们生产生活的需要。
在澜码科技之前,周健也算是连续创业者。被问及为何选择再次创业?周健表示:“前几段创业经历给我带来了很多灵感,尤其是我在做CTO时,看到了很多自动化的场景,但由于AI 1.0阶段AI的成本太高,有些场景很难实现。”
可以说,大模型的出现顺利把AI 1.0带入到AI2.0阶段。而在这一时期成立的澜码科技想做的正是用新的AI技术解决之前的难题。
“很可能未来很难再次遇到像今天大语言模型这样的宏大浪潮和机遇。”周健补充说,大语言模型的出现,开启了软件新范式,过往企业数字化转型中尚未解决或解决的不够好的问题,今天伴随着大语言模型的出现,都能够解决了。
周健过往在依图科技和弘玑RPA的连续创业经验,使得他更知道市场需要什么。在他看来,接下来比拼的就是谁能更好的应用大模型,就像当初微软使用英特尔的CPU一样,只要应用的好就能在大模型时代脱颖而出。”
谈到未来,周健给澜码科技定了一个目标,即“要有挑战世界第一的勇气。”
以下是AI科技评论和周健的对话:
基于大模型创业,比拼的是谁能更好地应用大模型
AI科技评论:能否介绍一下您的工作经历?
周健:我是1999级入学上海交大,2002年拿了ACM世界冠军,2006年硕士毕业时我拿了三个offer:一个是微软亚洲研究院,一个是谷歌,还有一个是在上海的MSN。那个时候谷歌刚进入中国市场,因为我有亚洲首个ACM冠军团队成员的背景,对Google有宣传效果,所以李开复说我是他的50个“闭门弟子”之一。
当时微软亚洲研究院的沈向洋打电话给我,我去北京和沈向洋当面One&One,但那时我觉得谷歌更互联网思维所以还是选了谷歌。现在回过头看,也还是会选谷歌。
AI科技评论:因为当时谷歌离实践比较近?
周健:主要是那批人都很强。当时我的mentor 是黄峥,我旁边坐着有宿华,还有洪锋也都是那一届的。
到了2008年我就进入了阿里云,到2011年时,因为公司和自己个人多方叠加因素我离开阿里云,回到上海加入了Media V,直到2013年离职后短暂的开启了一段创业,再到后来我加入依图科技和弘玑RPA。
AI科技评论:您2013年离职后,其实就开始创业了?
周健:是的,2013年从Media V出来时产生了一个错觉,当时hadoop在国内火起来了,所以就打算做分析日志,做hadoop。当时阿里用hadoop已经有四、五年时间了,百度也用了,Media V也用了,但实际上国内较国外还差的远。
AI科技评论:回过头来看,您认为不成功的原因是什么?
周健:不懂商业化,因为之前一直做纯粹的技术,在阿里时我是在后台,在Media V时候虽然稍微接触了一点业务,但实际上也是纯后台,比如广告行业的大数据分析,你不知道研发成本是多少,不知道毛利率是什么,不知道怎么定义客群,不知道产品的价值是什么,销售体系也不明白,当时就只知道日志分析是有可能会出圈的、Spark是个浪潮,这种情况下创业很难成功。
AI科技评论:那当时为什么选择创业?
周健:当时见了IDG的李丰和蓝驰的陈维广,陈维广给了我一个TS,我就被“架”上去了,所以就找了合伙人,花15万美金建了一个三、四人的技术团队。但是问题也就来了:你的客户在哪儿?你的产品是什么?能提供什么价值?后来发现4个人什么都做不了,所以8个月后就把公司关掉了。
AI科技评论:那段创业对您最大的影响是什么?
周健:因为有了CEO的视角,所以后来不管是看弘玑还是依图都可以感同身受,可以更容易带入和理解CEO的感受、压力、困难、预判等等,相对应地,当你有CEO的视角再去近距离观察别人创业时,能够吸收到的经验也更多,体会也更深刻。这是最重要的。
另外,在创业的过程中我也积累了很多资源,这10年资方是看着你成长起来的,我现在的股东就是当时创业期认识的。
AI科技评论:再次选择创业做澜码,又是为什么?
周健:在依图我完整经历了一个技术从创新至普及应用到全社会的过程,我今天选择做基于大模型的创业其实是在这段经历中学习到的。2014年时人脸识别技术是不能用的,直到2021年人脸识别这项技术才开始实现大规模通用。我们原来做人脸识别,只能做一比一认证,之后做人脸门禁、人脸闸机,人脸布控,人脸搜索等,主要是在工程方面做了很多“妥协”,这是我经历过的。
今天大语言模型从技术到商业的发展曲线也是一模一样的,唯一的区别在于,以前依图的算法团队是依图自己组建的,这就意味着依图要自己承担底层模型的研发风险,但今天众多大语言模型公司在投资者的支持下进行技术探索,我们用市场化的手段去购买使用就可以了,因此,澜码免于承担底层大模型研发的风险。
AI科技评论:相当于不用承担风险了,只考虑怎么用大模型就好了?
周健:准确地说,是我不需要负责大模型智能能力的提升,就像当年微软使用英特尔的CPU一样,CPU的研发风险由英特尔承担,而每隔一年半的时间,微软使用到的CPU在成本相同的情况下计算能力会翻一倍,或者计算能力一样,成本降一半。
我们现在是基于大模型做产品和商业化。做大模型产品,比拼的是谁能更好地应用大模型。相当于虽然大家都能用,但我用的好、我就是领先的。就像当年微软用英特尔,微软用的好,微软就把其他软件全部灭掉了。(欢迎添加作者微信ericahss1224,交流更多国内大模型背后的故事)
大模型的能力会持续提升,成本会持续降低
AI科技评论:选择基于大模型做新一代的自动化平台,是受哪段经历的启发?
周健:主要是做RPA给我带来的新视角,现在我做得是人和系统的连接,这样我就能把重复性的劳动问题解决。但不同的是,RPA替代的是一线业务人员重复性的工作,解决的是工作效率问题,我们今天在大语言模型下提供专家知识和经验,解决的是业务流程的质量问题。
其实我做RPA时,就看到了很多自动化的场景,我知道财务有什么场景,HR有什么场景,国家电网有什么场景,银行有什么场景,保险有什么场景,但由于AI 1.0阶段的AI技术不成熟,成本也非常高,所以很难实现。
AI科技评论:具体有哪些场景?
周健:现在数字化程度较高的企业内部肯定有大量的系统,比如供电所有大量的基层单位和大量系统。假如供电所要换电表,起码要涉及计量系统、营销系统和物资系统三个系统,以及六次操作。
首先要把这个电表里的数字记到系统里;第二,把电表拆下来,这个电表和原来电账户就没关系了,要登记 ;第三,由于这个电表在物资系统里已经是一个二手的物资了,还要再登记一次;第四,新电表装上去,这个电表的ID在物资系统里,激活之后要把这个电表和账户连接起来;第五,新电表上的读数是什么,计量系统里又一个开始计费的起始点,这六步操作完,还有很多复杂的工作,如果没有RPA,是非常繁琐复杂的。
银行里信贷额度的审核场景也是类似。假如要做一家网红饮品公司的信贷额度授信审核,首先要拿到它的财报做分析,然后要去法律系统里看看它是否有纠纷,把这些数据收集好,可能有40列信息,然后还要看央行规定是什么样的,总行规定是什么样的,都要整理好,然后做决定——是要维持授信额度不变、增加授信额度、减少授信额度还是暂停。如果没有RPA大概40分钟才能做一个审核。
全社会不可能有一个超级系统,一定是要有连接的。
AI科技评论:所以AI 2.0是在解决以前不能解决的问题?
周健:对,大模型出来之后,很多以前不能实现的工作,都有可能实现了。
澜码科技实际上是一家AI原生的公司,我尽量不让员工去写软件菜单,因为我觉得这些都是意义不大的工作,做完之后就被扔了。就像现在 SaaS 公司,因为要服务现有的客群,所以必须去做传统意义的拖、拉、拽,但其实这些事情已经没有意义了,最后一定是对话式的UI。
AI科技评论:较AI 1.0,AI 2.0不仅技术水平提升了,也降本增效了?
周健:AI 1.0阶段,机器学习、深度学习确实把门槛降低了,但成本是非常高的,尤其是AlphaGo出来后,人力成本急速上升,再加上移动互联网时代到来,拼多多、字节等大厂出现,极大拉高了人力成本。
我在依图时,负责依图的研发招聘,最多的时候一年招了40个清华的学生,2016、2017年只要是AI的硕士研究生年薪就是60万起,显然这样的人力成本根本赚不回来。再加上当时的数据、算力的成本都非常高。
进入AI2.0阶段,因为有了提供大语言模型技术的公司,市场得到充分竞争,使得每隔一年成本一样的情况下,大模型的智能水平肯定会翻一倍,反过来智能水平一样的情况下,成本会降到原来的二分之一到三分之一。
AI科技评论:澜码现在主要服务哪些客户群体?
周健:猎头招聘是主攻场景之一。初级猎头搜候选人主要通过猎聘、脉脉、BOSS直聘等,有3、4年工作经验的猎头可能不需要了,因为他们都会有一个候选人私域库,大概2000人左右,这2000人平均每两、三年要换一次工作,这部分信息的更新是一个很大体量的工作。
此外,猎头顾问基于私域库寻找候选人的工作方式,对顾问来说准确率高,工作量也小,但是很难把打电话沟通或见面沟通时有价值的数据补充到私域库中,只能在私域库自己去打标签,比如今天和候选人打电话说了啥,当时自己记下来了,但时间一长就忘了,私域库的管理效率和质量都不高。
大模型出来后,腾讯会议之类的软件有了语音识别的功能,就可以把打电话沟通等交互过程中的“活”数据整理、提炼、存档,这些都是大模型赋予的能力。
大模型催生了第四个新的范式,可以叫对话式或者匹配式。现在的猎头工作是人岗匹配,抽象来说就是一个X space,x空间和y空间。x空间描述需求,y空间匹配需求。
大模型出来之后,对话的方式可以提高匹配效率,这是很典型的场景,也在更多其他场景适用,比如房产中介搜房源,设计师搜图,外包程序员搜函数、代码等。
AI科技评论:相当从猎头这个场景出发,先做了一个工具试试?
周健:其实最终语义的匹配肯定是一个大的场景,这个场景在所有专业场景、企业里都能用到。我们只是把猎头作为其中一个突破口而已,我们还有一个战略合作伙伴,属于行业Top3级别,营收在5亿左右,我现在已经在帮他做运营的工具。
我们之前也服务过金山办公,WPS中Excel表格就是我做的,比如说“请一班学生成绩前十名的家长,明天下午 2 点到办公室。”这是一个很复杂的需求,原来需要你在表格里面查询、检索,再去微信找人、发信息,现在有了大模型就很容易智能化地处理了。
大模型不是万能的,技术研发也不存在弯道超车
AI科技评论:作为应用方,澜码怎么和大模型合作?
周健:因为大模型的“幻觉问题”和权限问题,终端用户或者甲方很难和大模型直接合作,肯定是需要澜码科技这样的中间厂商。
以猎头场景为例,比如找阿里P9级的35岁的员工,如果没有,放宽到38岁,有三个。那是应该优先问38岁,还是阿里系、还是P9,这是专业知识的范畴了。
在我看来,现在的大模型是一个重要的模块,如果用OpenAI的说法就是,Agent底下有一个领域模型。比如识别简历中的985、211高校这样的信息,需要用大模型训练吗?其实不需要,所以大模型不是万能的,很多事情不需要、也不应该用大模型来做。
AI科技评论:国内外的大模型,都有用过吗?
周健:没必要把所有的大模型都用一遍,只需要用目前水平最高的模型就够了。所以我们是在用GPT 4做训练。比如我有10个问题,我会让GPT 4 帮我破解这10个问题,破解完我再让 GPT 4 帮我确认答案、评价答案,然后训练出一个小模型,解决场景问题。
AI科技评论:怎么保障隐私问题?毕竟这个问题还是很敏感的。
周健:个人隐私保护法规定数据简历不能随便出境,所以我会把姓名、电话、年龄这些涉及个人隐私的问题摘出来,只把院校、项目经历给大模型,相当于一个表,我只给了表头的内容,表里的内容我不会给出去。
AI科技评论:目前,国内大模型还是非常火热的,您怎么看?
周健:AI新闻和AI不是一件事儿,一个创业公司不可能一开始就做千亿参数的模型,因为这件事情非常烧钱,完全没必要。应该循序渐进,先训练一个6B的,再训个13B的,再训个33B的...不见得真的这样,但是过程肯定是这样的。
智谱、MiniMax很早就开始做这件事情了,所以他们能取得现在的成绩是在意料之中的。但是有些公司未必走过这个技术路线,但对他们来说,不可能先发一个13B的模型,他只能说我已经有千亿模型了,但实际上水平还没达到。(欢迎添加作者微信ericahss1224,交流更多国内外大模型背后的故事)
AI科技评论:所以国内的模型水平还很难赶超OpenAI?
周健:这个问题和行业人士探讨过,如果想做GPT4起码需要25000张卡、训练8个月的时间。从目前来看,国内大模型的水平不可能比OpenAI强,大模型是不存在弯道超车的。
创业是九十九死一生的事情,要有挑战世界第一的勇气
AI科技评论:较之前,您认为现在创业哪些东西是最重要的?或者和之前有什么不一样?
周健:我觉得没成功之前很难说这句话,因为创业是 99 死一生的事情,每次创业的环境不一样。我在依图经历过40亿美金,弘玑也达到过6、7亿美金,如果现在我只做二、三十亿,或者两三亿美金被收购了,对我来说没有任何意义。如果做到10亿美金上市的话,算是及格。
很可能以后很难再遇到这样的浪潮了,这辈子如果有冲百亿的机会,我肯定会冲百亿,有千亿我也肯定会take risk,最后很可能就是大赌大输大赢,小赌小输小赢。
AI科技评论:作为初创企业,澜码的优势是什么?
周健:其实现在是在用未来的技术解决过去的问题。过去的从业经验使得我能很好的利用大模型的优势,再就是市场端我早就探索过了,我知道今天市场需求是什么样的,我也知道他们付费的意愿。
但也有一个难题,是排序的问题——我应该先解决哪个问题、再解决哪个问题。反过来,大模型迟早会突破,所以你的目光只要足够远,你等着它突破就好了。
AI科技评论:澜码以后的规划是什么样的?
周健:我给澜码订的目标是要有挑战世界第一的勇气。
我们的目标是做企业的入口,到时候企业不用登陆SaaS,因为我是对话式搜索,只需要和我讲你的需求,比如我要请假,我要报销,我要分析某个门店的情况,只需要讲就行了。
五、六年前我写过一篇文章说,我想做一个行星级的智慧系统,那时就看到了一个技术趋势说摩尔定律要停了,这就意味着技术的每一层芯片层、操作系统、数据库可能都会发生变化,只不过今天以这种形式表现出来了。