- 产品中心

- 关于我们


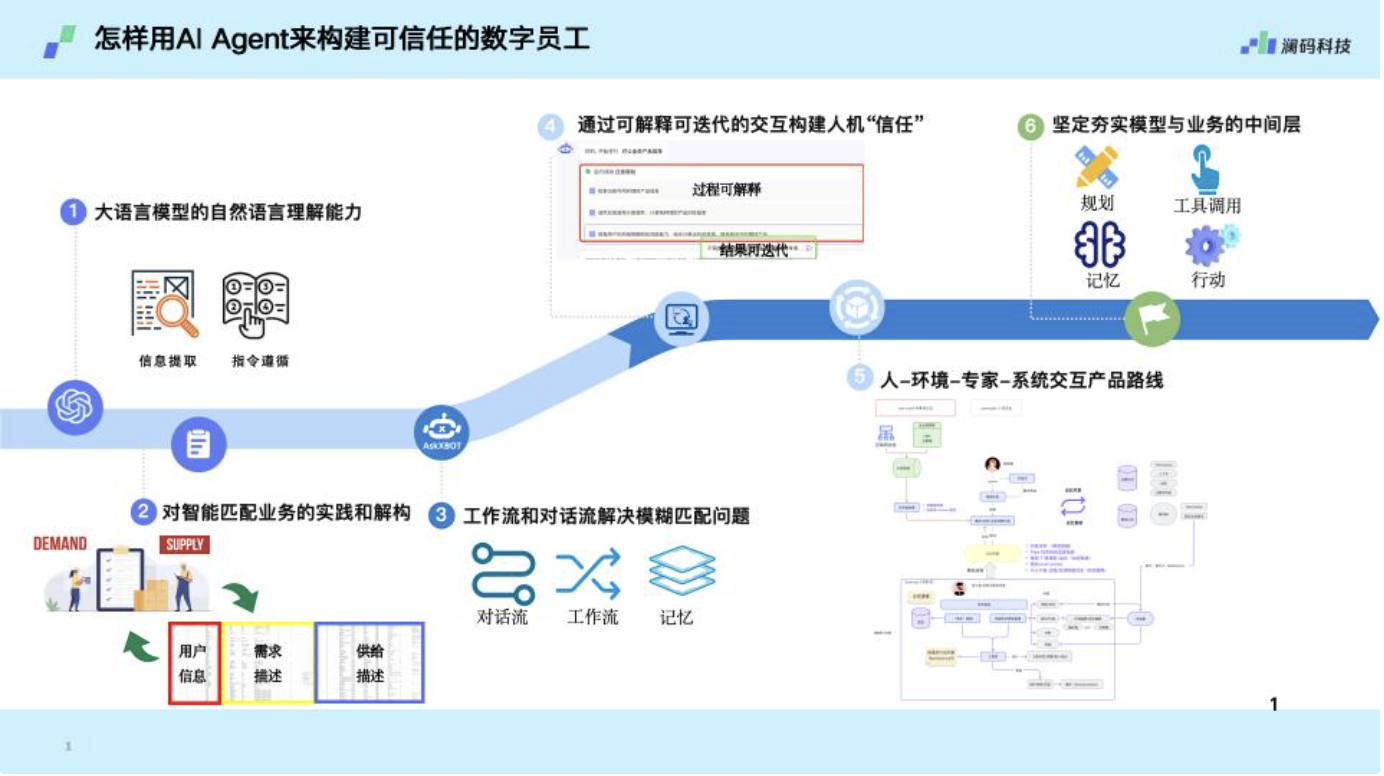
Agent出现后,人机交互会发生变化。
11月30日至12月1日,由中国科技产业智库「甲子光年」主办的「致追风赶月的你」2023甲子引力年终盛典在北京顺利举行!
百余位嘉宾齐聚一堂,聚焦产业前沿话题,剖析科技产业风口,总结分享这一年来的里程碑事件和行业变量。站在历史长河审视当下,ChatGPT与AI大模型的诞生,或许会成为对整个互联网文明,乃至整个工业文明的一次颠覆。科技与产业深度融合下,一个崭新的时代正在来临。
现场,澜码科技创始人、CEO周健为观众带来了主题为《专家知识的数字化是AI Agent落地的制胜之匙》的分享。
周健认为,Agent出现后,人机交互会发生变化,专家知识又是其落地的一个重要前提条件。专家的个人知识可以通过标注的方式不断丰富和完善,通过不断标注来为系统提供反馈,进而形成一个所谓的知识闭环。这样系统就能持续地从专家的反馈中学习并提升性能。
以下是澜码科技创始人、CEO周健演讲实录,「甲子光年」整理删改:
感谢主持人的介绍。我先简单介绍一下我们公司,澜码科技是我今年创办的企业,一直以来我们都致力于大模型的应用落地。最初,还没有“AI Agent”这个词,当时讲的更多是自动化,探讨如何在大语言模型上构建一个自动化平台。大概从今年5月开始,OpenAI提及的AI Agent概念,让我们意识到,这就是我们所追求的方向。我们更多专注于企服领域,但今天我想与大家分享的是,在这大半年的探索中,我们发现专家知识是AI落地一个十分重要的前提条件。
1.有了AI Agent,人机交互会发生变化
陆奇博士在今年初提过,未来软件开发范式将会发生转变,会有三代信息系统的演进。目前的信息系统主要是对物理世界的记录或感知。从大模型的角度来看,它是一个推理系统、知识系统,负责将各种数据压缩成一个模型,用科幻小说的说法来形容,它就像一个“缸中的大脑”,并不直接与世界相连。
从过去的自动化视角来看,现在可能是正在构建所谓的“行动系统”。就像是一个神经中枢,负责解读“缸中大脑”的一些思维、输出,或者我们将它带进去输入,我们负责任务的拆解,与实际的真实环境互动。这个定位与大模型和过去的系统都有所不同,它中间有一个很重要的连接器,这也是我们对整个AI Agent的理解。或者说,AI Agent的底层是大模型,但中间一定需要有一个行动系统来完成实际的智力大脑与真实世界之间的互动。
再进一步解释,这里的中间层则是Agent,等于LLM+Plan+Memory+Tool use。有了Agent,人机交互会发生变化。传统的1.0时代,AI更像是其中一个“环节”,例如人脸识别或OCR,微软的Copilot则是指我们有多轮的对话,但它仍然是“拨一拨,动一动”的模式。
AI Agent需要有自己的领域,这些领域不限于大模型,还包括知识图谱或5000行的代码。在整个Agent环境中,大语言模型主要负责与人互动,并将其翻译为具体的API。这就是我们所理解的基于大语言模型的智能体。
建设AI Agent说起来容易,但实际上却面临着许多挑战。这里我列举一些澜码从自动化视角所遇到的挑战,我相信在座的许多同行也会有类似的感受。在企业流程中,我们总是有一线业务员工和标准操作流程(SOP)。SOP对于一线业务员工的需求是什么?首先需要理解、感知、思考、行动。在过去1.0的时代,理解和思考是难以实现的,或者说需要付出巨大的代价。
如今有了大语言模型,我们获得了极其便宜的语言理解能力和一定的逻辑思考能力,于是我们有机会实现SOP的自动化和智能化。从工程视角来看,一个SOP通常由数据、文档、应用、流程组成,比如过去的RPA,主要解决了应用连接的问题,而现在的大语言模型能够进行所谓的Doc2QA,即理解文档内容,所谓的对话式BI,则是处理数据,而BPM则通过低代码解决了很多流程上的问题。
在产品架构的底层,我们设立了一个技能中心,其主要目的是封装各种大模型。考虑到现今大模型对算力的需求、开源情况以及各种SaaS的价格差异,封装肯定是需要的。目前,我们主要针对数据、文档、应用和流程进行了分别封装,以提供基本的功能,例如文档问答或通过文本调用API等。这些都是相对抽象的操作,但我们在底层的技能中心里进行封装,并配备了相应的数据集、实验平台,以确保我们的算法工程师或交付工程师能高效地摸索出来这套工具链。
在架构的上层,我们强调了一个重要的部分,即知识中心。知识比数据更为抽象。为什么要强调它呢?以简历搜索为例,当我们需要了解什么是“985”或“211”高校时,我们可以用数据库的方法轻松获取这类信息,但如果你去问大语言模型,它可能会出错,即使你对它进行训练、微调或预训练,从成本效益的角度来看也是非常不划算的。但实际上,有时只需要编写10行代码,从网上整理相关信息,我们就能轻松地获取这个答案。
再比如,什么是“工作稳定”?这可能是一个难以用自然语言明确描述的概念,因为不同的行业、岗位和职级都有其特定的属性,这其实就是专家知识。那么如何沉淀这些知识呢?再比如在文档中,商业世界中最有价值的100个文档,如财报、合同、招标书、投标书、简历和研报等,我们都可以利用专家开源的公开知识进行提前整理,使其沉淀在我们的平台上。在拥有了一定的技能和知识沉淀后,任务中心就变成了一个可以拖、拉、拽或者一个Chain的方式,把这些技能和知识组装成一个能与人互动的Agent,这个Agent能够帮助业务员工直接完成任务,同时沉淀各种互动数据,进而形成数字化。
我们参考了企业中的知识维度,这是日本的一个理论,即SECI。在当今大语言模型成熟的时代,我们有机会重新审视和改进过去企业中的知识中台,使其不再仅仅是一个信息系统,而是一个可以通过Agent方式沉淀和收集知识的平台。即使员工离开,这些知识仍然可以被保存在我们的Agent中。
举几个可能的例子,我们应该带着这样的理念在企业内部推进企业知识创造和知识管理的数字化。前面可能讲得有些抽象,这里我具体谈一下澜码今天落地的一个专业场景。我们的目标是使用总部的专家来赋能集团的业务单元。
许多企业如保险代理、猎头公司和零售公司,都有大量的专家,但他们无法覆盖到所有需要帮助的人,因为一天只有24小时。但可能有100个或者1000个一线的店员、店长或更多的人员需要辅助,专家无法满足这种需求。我们希望解决这个问题。
2.组装后AI Agent就像是专家分身
从另一个角度来看,人类如何获取技能是一个有趣的话题。从新手到高级新手的过渡相对容易,主要是通过学习和记忆大量的用户手册。但是想要变成胜任者,即能够在适当的场景中运用适当的知识,这就变得相当具有挑战性。专家在这方面有着深入的理解,但主要问题是如何将这些知识传授给AI Agent,使高级新手在AI Agent的辅助下达到胜任者的水平,这是我们目前认为最有可能解决的一个场景。
AI Agent的落地应用将带来巨大的价值,不仅在提升人才技能方面,而且在企业整体收入增长上都会有很大影响。我们期待通过这种技术改变整个人才结构。举一个具体的例子,在招聘领域,我们可以利用专家整理的各种技能和预定义知识,组装成一个专家Agent。最终用户在使用时,只需要用自然语言描述需求,系统就能为其找到符合要求的简历。
在这个过程中,最有意思的一点是专家的个人知识可以通过标注的方式不断丰富和完善。例如,当专家在辅助100个员工的过程中发现Agent的某些表现不够理想时,他们可以通过标注来为系统提供反馈,从而形成一个所谓的知识闭环。这样,系统就能持续地从专家的反馈中学习并提升性能。
此外,专家还拥有一类的知识,那就是他们清楚如何设置流程。在生产供应链、财务账期或开发版本管理等各个环节中,都有这样的需求。过去,我们在宏观层面上依赖专家的知识。如今,各个环节上都有AI Agent的辅助,这使我们能够贯通更多的数据,将整个上下文都沉淀下来,从而进一步提高整个端到端的企业流程价值,无论是效率还是吞吐量。
举一个实际的例子,当我们管理流程时,通常都会有一个Dashboard来分析具体情况,管理者则可以在宏观或运营层面上提出问题。但以往,Dashboard的信息是静态的,做完之后可能是僵死的,如今在大语言模型的辅助下,专家可以针对数据提出问题,从而获得更深入的数据分析,甚至可以利用大语言模型处理过去难以处理的数据,如员工的周报、邮件中的审批记录或聊天记录等,其实都可以被大语言模型利用起来,进而为管理者提供帮助。
此外,我们还可以增加一些所谓的分析SOP,像传统的五力分析、鱼骨图等都是可以通过对话进行分析和记录的。这样,专家的分析思路就形成了新一轮闭环的专家知识,可以被存储和进一步利用。实际上,在我们遇到的一些案例中,已经发现了许多原先无法实现的事情。原先只有一个30或40人的小团队,现在要赋能1万或10万人,怎么办?这其实是可以通过Agent进行连接的。
最后,我想为大家快速展示一下我们当前的产品。过去这些事情也能做,不过要编写代码,但现在只需要专家通过这个界面搭建一个Chain就可以完成这项工作。
某种程度上说,其实就是专家可以用自然语言与我们的AI Agent进行对话,共同沉淀知识并生成工作流。这样,从设计界面到实际使用,我们包装出来的Agent就像是专家的一个分身,能够协助业务员工出色地完成工作。当然,我们还可以将过去的代码、RPA、低代码、BI、爬虫、OCR模型,以及其他如文生图、ASR、TTS等技术全部嵌入其中。
通过端到端的对话式方式将Agent全面包装起来,使得专家与一线业务员工能够轻松地进行互动。此外,我们还有Market Place,可以将专家的技能和知识封装起来,方便调用。
这就是我今天全部的分享内容,希望能够给大家带来一些启示和帮助,非常感谢大家的聆听!