- 产品中心

- 关于我们
澜码CEO受邀出席新消费科技论坛,分享AI Agent如何赋能新零售 


算力加进去,生产力“长”出来
把专家知识赋能给 AI Agent
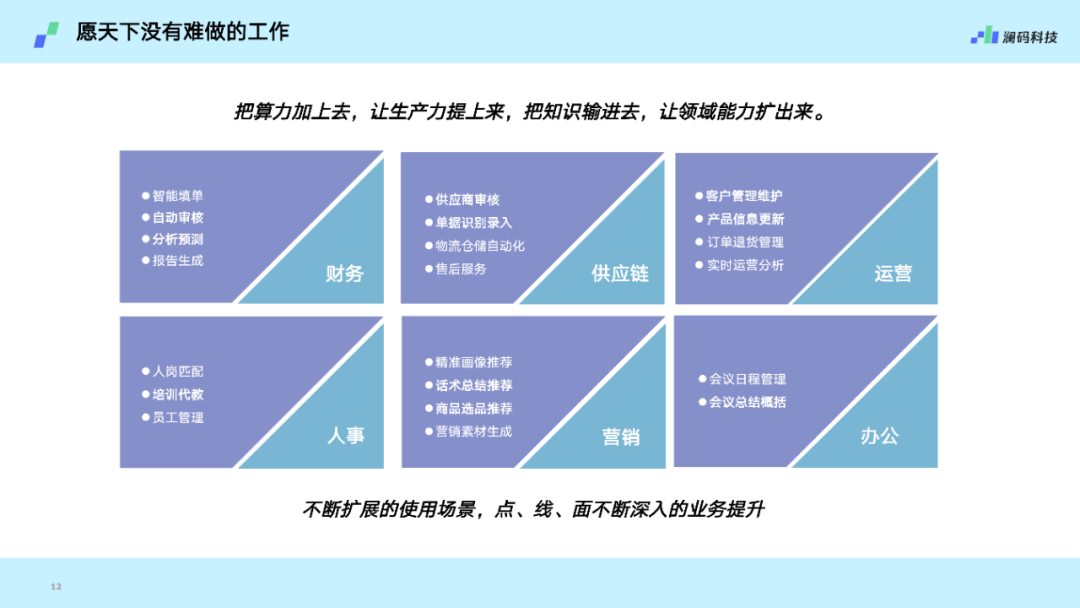
愿天下没有难做的工作
在零售行业,今天大语言模型最适合的是做运营分析,一方面可以通过对话式BI发现问题,再结合专家知识进行辅助诊断。
另一方面,由于本身有自动化的实现能力,就能够通过集成 RPA等工具把动作给执行掉。
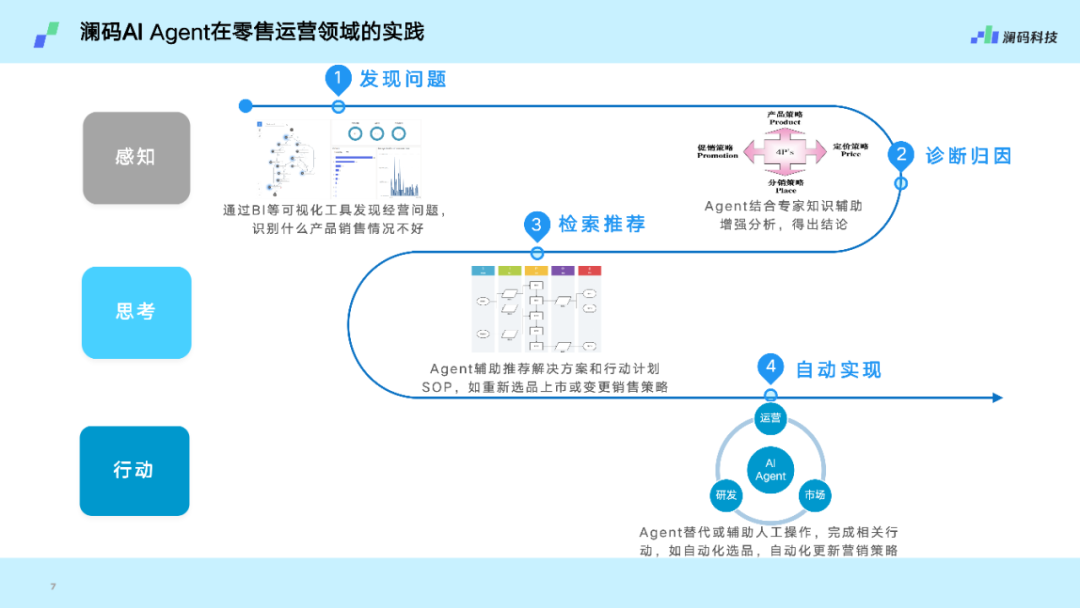
在零售行业,今天大语言模型最适合的是做运营分析,一方面可以通过对话式BI发现问题,再结合专家知识进行辅助诊断。
另一方面,由于本身有自动化的实现能力,就能够通过集成 RPA等工具把动作给执行掉。